
图片引自:https://www.percona.com/blog/2019/07/30/parallelism-in-postgresql/

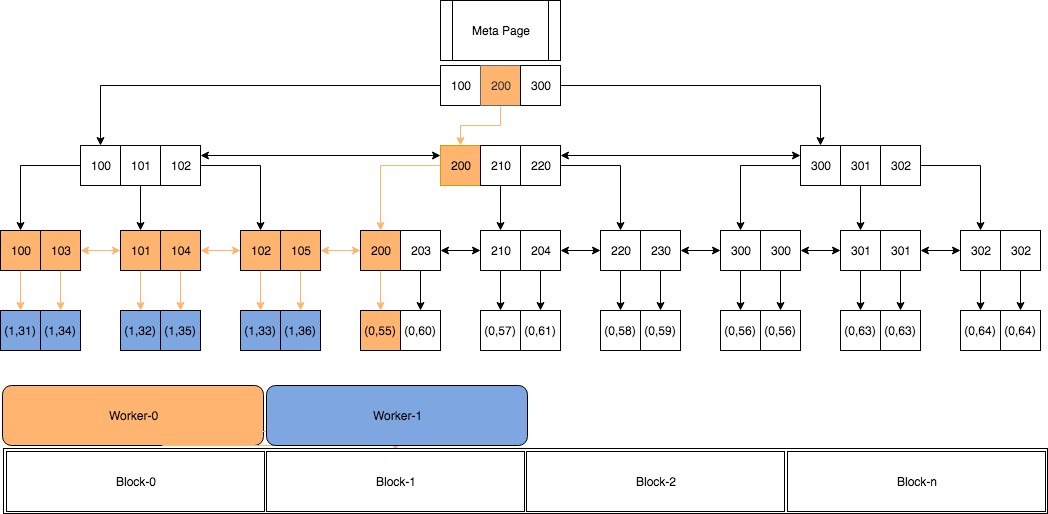


Notes on PostgreSQL Parallel Query.
__________________________________________________________________________________
standard_ExecutorStart
|
|
\|/
InitPlan—>
|
\|/
ExecInitNode
|
|
\|/
ExecGather—》 ExecInitParallelPlan—》 ExecSerializePlan
| |
| |
| |InitializeParallelDSM DSM, dynamic shared memory, dynamic shared data.
| 在开始执行的时候, 首先使用shm_toc_estimate_chunk,shm_toc_estimate_keys来
| 进行DSA(dsa是属于什么?)空间进行估算。 其中会保存,fixed-size的状态信息。
| query string,serailized plannedstmt, serialized paramlistInfo,每个worker
| 中的BufferUsage信息。Walusage, tuple queue由workers对其中进行写入的信息。
| 有写入就有需要读取的,reader信息。 (segment table of contents)。
|
| 在初始化完相应的状态信息后,可以进行launch workers—LaunchParallelWorkers的动作。 即:开启相应的workers.
|
|
| BecomeLockGroupLeader 首先要构建一个成为leader的worker,如果还没有一个leader出现的话。
| BackgroundWorker类型描述了后台的各个worker的情况。
|
| —》 LaunchParallelWorkers 该函数中启动相应的worker进程。
| |
|
|
|RegisterDynamicBackgroundWorker 注册相应的backgroud worker.
|
|
|
|
|—》 ExecParallelCreateReaders 构建相应的result tuple reader. TupleQueueReader数据类型;
|
|
|—》 gather_getnext 获取下一条记录.
| |
| |
| | —> gather_getnext 读取下一条记录.
| | |
| |—> gather_readnext 读取下一条tuple记录。
| | |
| | | —》 TupleQueueReaderNext
| |
| |
| |—》 shm_mq_receive 从mq中读取一条tuple。
|
|—》 ExecProject 返回结果集;
|
|
|—》
ParallelWorkerMain
数据结构:InternalParallelWorkers, 数组描述了并行查询的worker的入口点。其中涉及了三个入口点。
static const struct
{
const char *fn_name;
parallel_worker_main_type fn_addr;
} InternalParallelWorkers[] =
{
{
“ParallelQueryMain”, ParallelQueryMain
},
{
“_bt_parallel_build_main”, _bt_parallel_build_main
},
{
“parallel_vacuum_main”, parallel_vacuum_main
}
};
通过查询概数组 InternalParallelWorkers 中的worker的入口点等信息,来获取具体并行信息。
ParallelQueryMain: 并行查询的工作入口点,在该函数中我们会使用worker进行具体的工作。
ParallelWorkerMain: 并行查询的worker的入口。
为啥我们需要根据函数名字进行查询出worker的地址? 因为有可能worker的函数地址在不同进程
的不同的地址空间内,因此,为了防止直接传递函数地址导致的core,我们使用函数的名字进行查找。
ExecInitGather/ExecGatherMerge
|
|
\|/
LaunchParallelWorkers
|
|
\|/
ParallelWorkerMain
|
|
\|/
LookupParallelWorkerFunction
BackgroundWorkerArray, BackgroundWorkerSlot 这些后台work槽中已经包括已经创建好的
后台worker进程。
数组InternalBGWorkers中给出了后台的工作worker的入口点。
BackgroundWorkerData数组中包含了类型BackgroundWorkerArray的数组数据。数组中包含了
worker信息。
BackgroundWorkerShmemInit
|
|
| BackgroundWorkerData = ShmemInitStruct()对该
RegisterBackgroundWorker , 在BackgroundWorkerList 链表中注册一个新的后台worker。
1:并行查询相关参数
1)创建索引,create table as, select into 并行参数。
[show/set] max_parallel_maintenance_workers = N;
2) 并行分区表的jion
[show/set] enable_partitionwise_join=[ON/OFF]
3) 并行分区表聚集
enable_partitionwise_aggregate=ON;
4) 并行hash计算
enable_parallel_hash=ON;
5) leader获取worker的信息
parallel_leader_participation=ON;
6)parallel append功能
enable_parallel_append=ON;
7) 总的worker的数量
max_worker_processes;
8) 所以session同时最大可并行度
max_parallel_workers
9) 单个job里最大的并行度
max_parallel_workers_per_gather;
10) 表顺序扫描或者索引扫描
min_parallel_table_scan=0;
min_parallel_index_scan=0;
11) 并行时优化器cost设置
parallel_tuple_cost=0;
parallel_setup_cost=0;
12)设置表级别并行
alter table table_name set (parallel_workers=N)