[root@Rings bin]# ./mysql -uroot –socket=../../data/mysql.sock
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 8.0.26-debug Source distribution
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
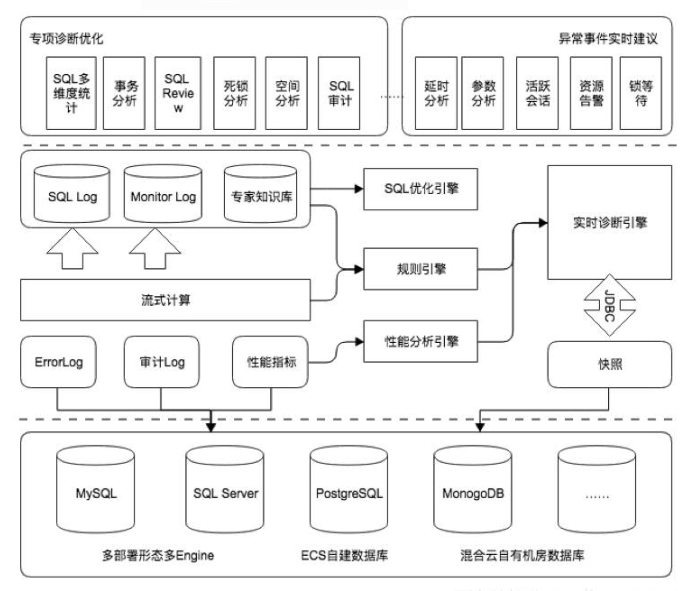
MySQL 8.0.26查询引擎一些零散记录:
准备些基本信息(表,数据等等)
create table sc(
sno varchar(10),
cno varchar(10),
score int
) ;
insert into sc(sno, cno, score)
values(‘2021’, ‘1990’, 95),
(‘2021’, ‘1991’, 90),
(‘2021’, ‘1992’, 78),
(‘2022’, ‘1990’, 70),
(‘2022’, ‘1991’, 80),
(‘2022’, ‘1992’, 86),
(‘2023’, ‘1990’, 60),
(‘2023’, ‘1991’, 70),
(‘2023’, ‘1992’, 83);
–课程信息
create table course
(
cno varchar(10), —课程信息
cname varcahr(10),
credit int,
priorcourse varchar(10) –前者课程
);\G
create table course
(
cno varchar(10),
cname varchar(10),
credit int,
priorcourse varchar(10)
); \G
–子成绩
create table sub_course
(
sub_cno varchar(10),
sub_cname varchar(10),
sub_credit int,
sub_priorcourse varchar(10),
par_cno varchar(10)
);
insert into sub_course(sub_cno, sub_cname, sub_credit, sub_priorcourse, par_cno)
values(‘sub_1990’, ‘小生物’, 5, ”, ‘1990’),
(‘sub_1991’, ‘小化学’, 4, ”, ‘1991’),
(‘sub_1992’, ‘小物理’, 5, ”, ‘1992’);
insert into course(cno, cname, credit, priorcourse)
values(‘1990’ , ‘生物’ , 5 , ”),
(‘1991’ , ‘化学’ , 4 , ”),
(‘1992’ , ‘物理’ , 5 , ”);
create table class ( —班级信息
classno varchar(10), –班级编号
classname varchar(10), –班级名称
gno varchar(10)
);
create table class (
classno varchar(10),
classname varchar(10),
gno varchar(10)
);
insert into class (classno, classname, gno)
values(‘c1’, ‘class 1’, ‘g1’),
(‘c2’, ‘class 2’, ‘g1’),
(‘c3’, ‘class 3’, ‘g2’);
create table student ( —学生信息
sno varchar(10), –学号
sname varchar(10), –学生姓名
gender varchar(2), –性别
age int, –年龄
nation varchar(10), –国籍
classno varchar(10) –班级编号
) ;
create table student (
sno varchar(10),
sname varchar(10),
gender varchar(2),
age int,
nation varchar(10),
classno varchar(10)
) ;
insert into student(sno, sname, gender, age, nation, classno)
values(‘2021’, ‘zhangsan’,’m’, 20, ‘CN’, ‘c1’),
(‘2022’, ‘lisi’,’m’, 19, ‘CN’, ‘c2’),
(‘2023’, ‘ali’,’f’, 20, ‘USA’, ‘c1′) ;
SELECT classno, classname, avg(score) as avg_score
FROM sc, (SELECT * FROM class WHERE class.gno=’g1′) as sub
WHERE
sc.sno in (SELECT sno FROM student WHERE student.classno=sub.classno)
and
sc.cno in (SELECT course.cno FROM course WHERE course.cname=’物理’)
GROUP BY classno, classname
HAVING avg(score) > 60
ORDER BY avg_score;
SELECT classno, classname, avg(score) as avg_score
FROM sc, (SELECT * FROM class WHERE class.gno=’g1′) as sub
WHERE
sc.sno in (SELECT sno FROM student WHERE student.classno=sub.classno)
and
sc.cno in (SELECT course.cno FROM course, sub_course WHERE course.cno = sub_course.par_cno and sub_course.sub_cno =’sub_1992′)
GROUP BY classno, classname
HAVING avg(score) > 60
ORDER BY avg_score;
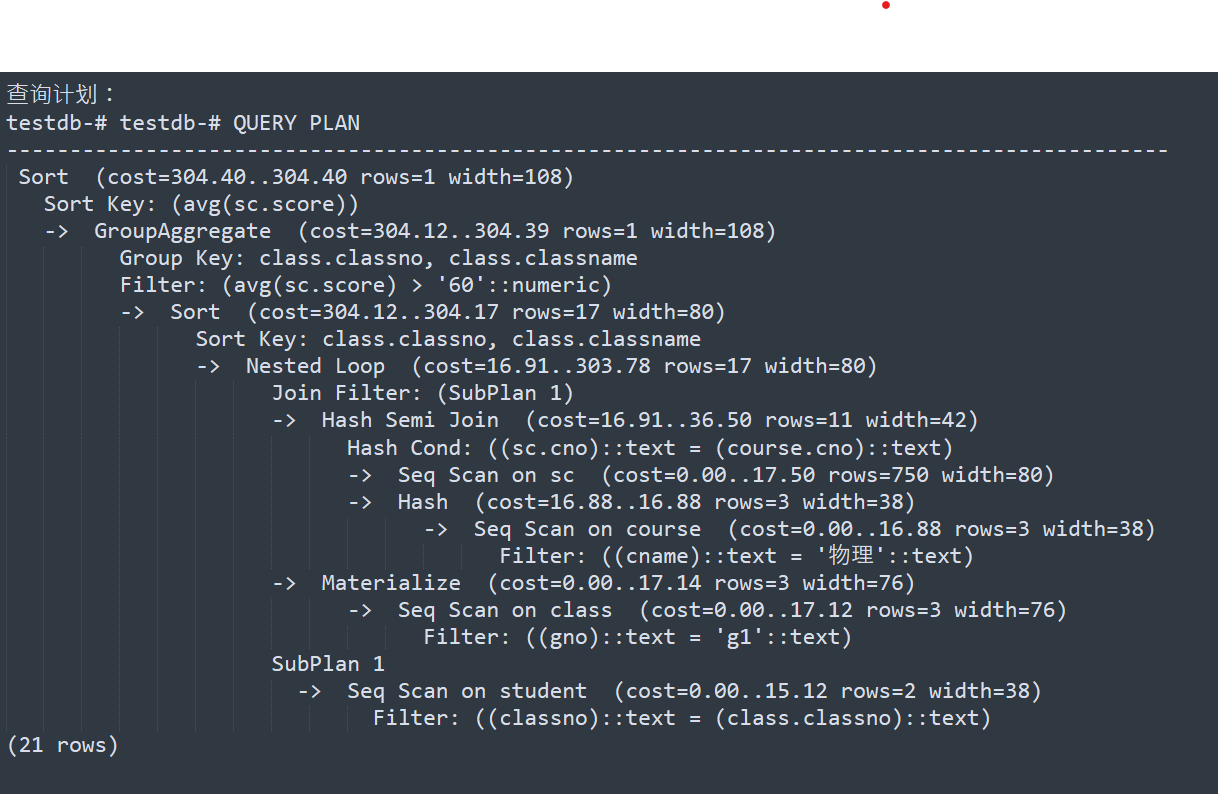
其中:为了对比分析,我们把PostgreSQL查询引擎的查询计划如下:
查询计划:
在query_expression的::execution函数中个,先进行prepare相关操作,
Query_expression::prepare–> prepare_inner->setup_tables-> set_wild等等; 、
还有设置相应的sj相关条件等信息;
然后就会走到相应的流程 query_expression中的execution流程继续相应的execution_inner操作
走到相应的query_expression::optimization中; 进入到query_block中的optimize中进行优化;
在prepare inner中,执行 query_block的 prepare操作。
如果在prepare的过程中发现,如果该表示dervied table,那么就会进入处理derived table这个环节
进行对于dervied table处理;
#0 TABLE_LIST::resolve_derived (this=0x7fe350b1df00, thd=0x7fe350001060, apply_semijoin=true)
at /home/leehao/mysql-server/sql/sql_derived.cc:254
#1 0x000000000389562b in Query_block::resolve_placeholder_tables (this=0x7fe350c312e8, thd=0x7fe350001060, apply_semijoin=true)
at /home/leehao/mysql-server/sql/sql_resolver.cc:1264
#2 0x00000000038923d3 in Query_block::prepare (this=0x7fe350c312e8, thd=0x7fe350001060, insert_field_list=0x0)
at /home/leehao/mysql-server/sql/sql_resolver.cc:239
#3 0x00000000038bd147 in Sql_cmd_select::prepare_inner (this=0x7fe350c39628, thd=0x7fe350001060)
at /home/leehao/mysql-server/sql/sql_select.cc:466
#4 0x00000000038bcb7d in Sql_cmd_dml::prepare (this=0x7fe350c39628, thd=0x7fe350001060) at /home/leehao/mysql-server/sql/sql_select.cc:383
#5 0x00000000038bd3ce in Sql_cmd_dml::execute (this=0x7fe350c39628, thd=0x7fe350001060) at /home/leehao/mysql-server/sql/sql_select.cc:521
在完成了对于mergable表的处理后,我们会继续处理natural join的情况。首先,会处理相应
的join row type的情况。
ITEM::fix_fields作用是将查询语句树上的item对象转为fields对象,这些fields对象是用于result的
情况;
执行相应的
Sql_cmd_dml::execute_inner, 而后进入query_expression::optimization进行优化;
JOIN::optimization,进行优化;
build_equal_items 来构建相应等式项, build_equal_items_for_cond 为条件语句构建相应的
等式;
#0 JOIN::make_join_plan (this=0x7f068cad91d8) at /home/leehao/mysql-server/sql/sql_optimizer.cc:5075
#1 0x000000000381154f in JOIN::optimize (this=0x7f068cad91d8) at /home/leehao/mysql-server/sql/sql_optimizer.cc:591
#2 0x00000000038c05c3 in Query_block::optimize (this=0x7f068c15f938, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:1805
#3 0x00000000039647af in Query_expression::optimize (this=0x7f068c15f1d8, thd=0x7f068c001040, materialize_destination=0x0,
create_iterators=true) at /home/leehao/mysql-server/sql/sql_union.cc:678
#4 0x00000000038be156 in Sql_cmd_dml::execute_inner (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:759
#5 0x00000000038bd766 in Sql_cmd_dml::execute (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:574
#6 0x00000000038433ee in mysql_execute_command (thd=0x7f068c001040, first_level=true) at /home/leehao/mysql-server/sql/sql_parse.cc:4436
#7 0x0000000003845396 in dispatch_sql_command (thd=0x7f068c001040, parser_state=0x7f0744579b60)
at /home/leehao/mysql-server/sql/sql_parse.cc:5033
make_join_plan构造相应的查询计划。(未完待续)