- 主要介绍SQL与XQuery之间相互转换的设计与实现
XML数据库管理系统(XMLDBMS)是近年快速发展的一种新型的数据库管理系统(DBMS),它存储和检索的数据是XML文档。 XML数据的检索和更新语言是有W3C制定的标准的XQuery和XQuery Update。XQuery系列语言基于序列数据模型(XDM),即XQuery中任意数据都是一个序列,序列由若干个有序的项目(item)的组成;一个item是一个原子值或者一个XDM节点,一个XDM节点是XML文档的7种节点之一。基于这样的数据模型,最自然和高效的XML数据存储方案就是把XML文档存储为节点。
在XMLDBMS中存储XML文档的实体称为容器(Container),一个容器中存储任意多个XML文档,而这个容器则由若干个数据表构成,这些数据表分别存储XML文档各个方面的数据和结构信息:包括节点数据,节点间关系,节点路径数据,索引,统计信息等。数据表存储的单位是数据行,一个数据表中含有若干个数据行,并且可以通过索引快速查找到特定的数据行。
关系数据库作为当今使用范围最广而且应用最为普遍的数据库已经被大量的应用在各个行业中,结构化查询语言(SQL,structural query language)则在关系数据库中扮演着重要的角色,SQL定义了一套完整的用来操作关系数据的语法:数据定义语言(DDL, data define language),数据操作语言(DML, data manipulation language)。其中的DML语言中包括了select语句,update语句,insert语句,delete语句等用来对关系数据库中的关系数据的数据进行查询,更新,插入或者删除操作。因而,这四类语句在关系数据库中被称作四大基本语句并被开发者广泛使用。
对于习惯使用SQL的用户来说,要学习并掌握使用一门新的查询语言-XQuery需要花费大量时间和精力。传统的方式是由数据库操作人员进行手工完成对SQL语句到XQuery语句的转换,在该种方式下无法做到进行大批次的转换,而且在转换过程中易出现相应的语法、语义转换错误。虽然现在有些关系数据库能以XML形式操作非关系数据,但其并非以Native方式存储XML数据,而是先进行数据拆分然后以关系数据的形式进行存储,而必然会导致系统处理非关系数据时系统性能低下。
本文提出了一种基于抽象语法树将SQL语句自动转为XQuery语句的方法,其可以使得用户无需进行数据的关系化处理的情况下使用非关系数据,只需将非关系数据以XML方式存储至XML数据库中,这样用户可以直接使用SQL语句以Native的方式对非关系数据—XML数据进行操作,从而解决了上述用户在使用关系数据库来处理非关系数据时所带来的问题。
随着当前互联网及其业务的飞速发展,在互联网应用大环境下产生了各式各样的数据,包括:关系数据和非关系数据。对于这两种数据来说关系数据则可以使用关系数据库以及SQL来对关系数据进行操作;对于非关系数据在我们将其组织成XML格式后,可将其以Native存储至xml数据库中,此时用户便可以使用XQuery语句来操作这些非关系数据。
在实际环境中在SQL与XQuery间的切换会导致数据库的使用者在一定程度上的困惑且容易在转换后出现各种语法、语义错误。为了避免在SQL与XQuery间转换的常规做法是将非关系数据在业务层进行关系化处理并在处理后存储至关系数据库中使用SQL语句进行操作。该种做法在实际环境下存在有些数据无法做到关系化且进行数据关系化该种增加了系统的处理负担,致使系统效率低下。因此我们提出的基于抽象语法树将SQL与XQuery进行转换的方法可以很好的解决上述存在的问题。
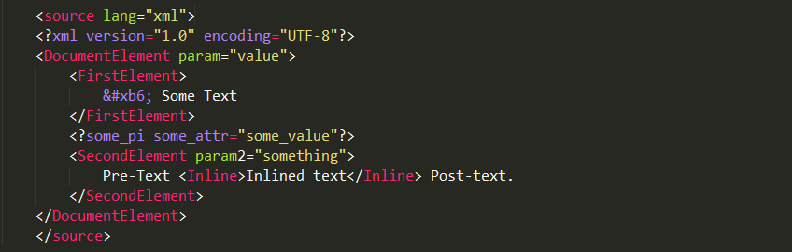
现有如下的xml文档(以后称之为Person.xml)。
对应一条SQL查询语句,其在真正被执行之前需要经历数个步骤,其中之一便是:根据其所定义的语法、语义规则由Lex/Bison来生成相应的抽象语法树。我们称该阶段为查询语句的解析(Parse)阶段。在查询解析阶段,系统会根据人们预先定义的语法,语义规则来对我们所要执行的查询语句进行解析并根据相应的语义规则生成相应的抽象语法树。
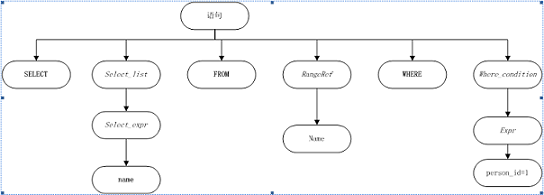
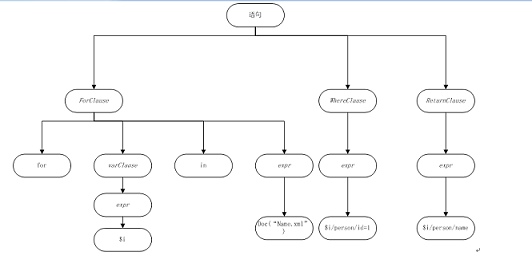
关系数据库中的SQL查询语句有一套语法语义规则,而XQuery也同样有自己的一套语法和语义规则。虽然SQL和XQuery具有截然不同的语法和语义规则,但是一条SQL语句和一条XQuery语句在经过Lex/Bison进行解析后会产生相类似的产出物:抽象语法树。抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是SQL查询语句或者Xquery查询语句源代码的抽象语法结构的树状表现形式。树上的每个节点都表示查询语句中的一种结构。比如,类似于select,where,for这样的语句均以分支的节点来表示。对于查询语句select name from Name where person_id =1和for $i in doc(“Name.xml”) where $i/person/id=1 return $i/person/name其在关系数据和XML数据库下其抽象语法树分别为:
为了能够更好以及动态配置SQL语句到XQuery语句的转换,我们在基于抽象语法树的基础上定义一组基于抽象语法树的转换规则,当一个SQL语句生成抽象语法树后,在该抽象语法树上面应用我们所定义的一组规则,将SQL语句所生成的抽象语法树的节点根据规则进行转换,将其转换为Xquery语句所需要的抽象语法树形式,在完成转换后,可以根据该抽象语法树生成该SQL语句所所对应的等价XQuery语句。
其中转换规则如下:
1)SQL语句中的where子句,将其转换为XQuery的where子句并将SQL语句中的where子句中的参数信息作为Xquery的Where子句中的参数信息。
2)SQL中的from子句,将其转换为XQuery中的for子句并将from子句中的表信息作为XQuery中for子句的doc或者container,collection函数的参数。
3)SQL中的select子句,将其转换为XQuery中的return子句并将select子句中的参数作为XQuery的return子句参数
4)SQL中的insert子句,将其转换为XQuery中的insert子句并将SQL的insert子句中的参数作为XQuery中的insert子句的参数。
5)SQL中的update子句,将其转换为XQuery中的replace子句并将SQL的update子句中的参数作为XQuery中replace子句的参数。
6)SQL中的delete子句,将其转换为XQuery中的delete子句并将SQL的delete子句中的参数作为XQuery中delete子句的参数。
对于上述的转换规则,我们可以将其保存至名为rules.y的文件中以便用户可以自定义转换规则,从而可以动态的满足不同用户的需求。
完成上述的转换规则的定义后,SQL语句转换XQuery语句的具体步骤可以分为如下的过程:
1)原始抽象语法树的生成阶段。
当一条SQL语句到达系统后,我们首先会将该SQL语句生成原始的抽象语法树,该过程由我们上述所说的Lex/Bison根据预先定义的SQL语义规则来生成。
2)规则读取阶段
在为SQL语句生成原始抽象语法树后,我们将预先定义的规则文件rules.y读入系统中以便后续步骤使用。
3)预定义规则rules.y应用阶段
将上述预先定义的转换规则应用于SQL语句所生成的原始抽象语法上,处理的规则为首先处理原始抽象语法树的叶子节点:根据叶子节点的类型分别应用上述的规则生成其所对应的XQuery抽象语法树上的相对应的节点,如果该节点的类型非系统所支持的类型,则系统抛出异常错误并终止规则应用。
当处理完叶子节点后,我们将已处理完成的叶子节点从抽象语法树中移除,此时该叶子节点的父亲节点由原先的非叶子节点变成叶子节点,然后对该新叶子节点应用转换规则,该节点所生成的XQuery抽象语法树的节点作为刚才所生成的已有XQuery抽象语法树节点的父节点。我们重复上述的处理过程直到SQL所生成的原始的抽象语法树都已完成规则转换。
4)XQuery语句生成阶段
在完成SQL抽象语法树的规则应用后,我们获得了一颗新的XQuery抽象语法树,在我们对其进行遍历后便可以获得其所对于的XQuery语句。
我们对SQL的抽象语法树的处理后,我们将得到一个其所对应的XQuery抽象语法树,我们可知XQuery抽象语法树在语义上与SQL抽象语法树是两棵等价的语法树,因此该种转换不会导致语义的丢失或者语义的转义。