
 收到会员通过通知了,😊
收到会员通过通知了,😊
分类目录归档:System
SQL Advisor相关
-
当前业界关于SQL审计的介绍:
-
Inception的相关做法:
-
SQL审核作为DBA以及RDBMS运维的一项重要的工作,其在现实中占据了大量的dba的时间和精力,使得较多的精力均放在简单机械性的工作。为了减轻DBA在此方面的相关工作,一些相应的自动化的工作相继开发出用以缓解DBA的工作。其中,去哪儿的incetpion作为使用较广泛且较为成熟的产品已经在许多公司内部所采用;
对应inception所完成的基本功能包括了:数据插入时候的配置;关于索引的配置;默认项的配置信息;修改表语句的配置;加列检查项的配置;修改配置项,删除索引等等;
虽然inception被大量的使用,但是其也存在着一定的问题:(1)其只是简单的语法和语义功能,并不解析并理解SQL语句,只是提取出数据库名,表名等;(2)其只是通过与线上信息进行比较;发现一些明显的错误;对应相当不明显涉及到与业务相关的错误或者是语句性能问题并无法检测;(3)其通过线上或者是beta数据库上执行explain语句来分析该语句的执行情况; (4)对应sql语句的执行情况,并未给出相应的优化建议。例如:该语句是否是在语义上高效;该语句执行后会影响到多少row记录;语句会扫描多少page,cache的命中率是否多少?等等诸如此类的信息均未给dba或者高级用户所提供;(5)关于每个数据库实例的数据分布情况描述。例如:对应数据库实例中每张表的数据访问情况,该表中的cardinality;该表中的mcv(most common value)等;这些关于当前数据库的运行状态信息;而这些相关的参数确是非常重要的影响sql语句执行性能,尤其会影响到查询计划的生成;对于不了解整个数据库的数据分布情况及每个实例的具体运行情况下,我们是无法对整个系统进行优化。同样,在描述了整个数据库集群的情况下,我们也可以反向的推动业务的优化; 下图为inception的设计架构图:

-
CloudDBA的相关做法
相对于inception的做法,clouddba采用了比较全面且系统的方法来实现,其不仅包括:sql的审计;同时,还真正的包含了数据库各个运行状态及相关数据分布的信息;例如:其会收集各个索引信息,数据分布情况,以此为依据为用户所需要执行的sql语句提供一个综合分析报告,例如:给出该语句的改写建议,通常是给出该语句所等价的最优执行语句;索引的使用情况,索引的创建是否是合理的。有无冗余列的存在或者是否需要创建组合索引等等;
clouddba采用了与inception不同的实现机制;从本质上来说,inception更多的是基于语法和语义规则来完成的sql advisor的工作; 其并未涉及到对应当前数据库运行情况的监控并未将数据库实例的实时运行参数考虑;而clouddba则是将整个数据库实例的运行数据获取下并已此为基础进行分析。从而给出对应语句的优化建议;其中对应监控的参数不仅仅包括数据库的相关参数,同时对应整个系统中的各实例的cpu使用,内存使用量,buffer cache hit ratio;latch contention;网络参数等等均有监控; 并已这些参数为基础,采用机器学习的方式来完成对各个参数的最优组合的求解工作;与CloudDBA相似,Tencent cloud的CDBTune也采用类似的技术路线; 下图为clouddba的架构图:
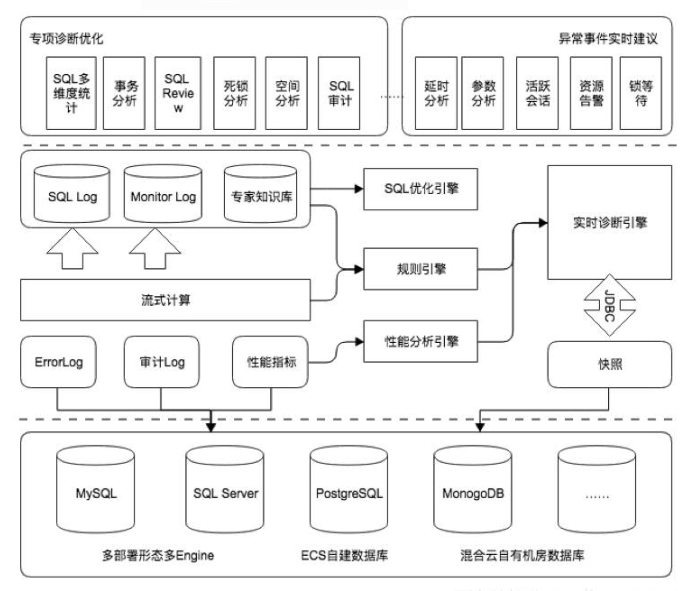
从上图中可以看出,其采用了动态和静态两种方式来对用户的workload进行分析; 在静态分析下,将系统中所收集到的各种类型的log送入规则引擎或者是sql优化引擎中并以此为输入从而给出关于对应该workload的静态分析; 而动态分析则会将该分析的结构反馈到各个具体的运行实例上,调整相关参数从而达到数据库实例的最优运行状态; 对应动态分析也是采用了machine learing相关技术来学习各个最优参数然后以次为依据动态的依据各个实例的当前运行状态,来调整相关的配置参数,从而使得实例运行达到最优的状态;
-
CDBTune的相关做法
CDBTune为Tencent Cloud推出的一个款智能系统调优的工具,其主要是面向dba对应整体集群的系统调优工作;
相比于现有业界通用方法,CDBTune无需细分负载类型和积累大量样本,通过智能学习参与参数调优,获得较好的参数调优效果。
数据库系统复杂,且负载多变,调优对DBA非常困难:
-
- 参数多,达到几百个
- 不同数据库没有统一标准,名字、作用和相互影响等差别较大
- 依靠人的经验调优,人力成本高,效率低下
- 工具调优,不具有普适性
总结起来就是三大问题:复杂,效率低,成本高。而CDBTune采用强化学习的策略来实现(具体实现介绍这里不做讨论)。
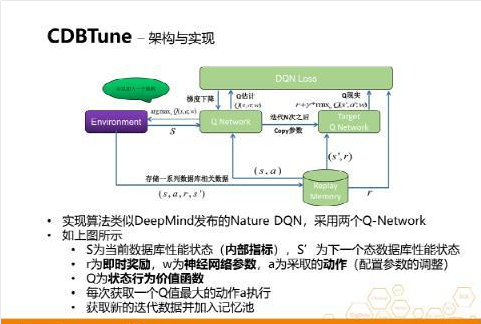
CDBTune与Inception和CloudDBA均有所不同,其似乎介于两者之间;所侧重的是对应整个数据库集群中各个实例的性能调优。主要是通过调整集群中各个实例的相关配置参数;
基于DQN智能调参的优势
-
- 化繁为简,无需对负载进行精确分类
- 调参动作更符合实际调参时的情况
- 无需获取足够多的样本来,减少前期数据采集的工作量
- 利用探索-开发(Exploration & Exploitation)特点,降低对训练数据的依赖,减小陷入局部最优的可能性
在实践过程中,我们也遇到一些问题:
-
- 选择动作实际运行,训练效率不高,训练周期长
- 对连续配置离散化处理,可能导致推荐配置的精度不高,收敛较慢
- 使用动作的最大Q值,导致Q值的过高估计问题
-
Oracle的相关做法
oracle提供了一个automatic database diagnostic模块,其中包括如下功能; (1)统计信息分析;如果统计信息陈旧活是遗失的话,那么需要提醒相应的dba进行统计信息的更新;例如执行相应的analyze命令; 通常如果是有相关选项将统计信息收集选项关闭的时候会提醒开启相应的统计信息收集选择;( performance_schema) events_statements_summary_by_digest;
(2)sql profiling 信息的输出; (3)访问路径分析; 索引信息是否是已经正确的创建或者是索引的使用正确; 推荐相应的索引创建;需要对相应的access path 进行分析;(4)SQL 结构分析; 对应语句的结构,语法,语义进行分析,来给出低性能的点。优化器通常会将Union用 union all; not in 用not exists来替换; 例如在 unique的上面我们就可以采用union all来替换union操作符; 比较union需要去重检查,而Union在在结构层上进行了保证数据的唯一性; (5)可选的查询计划分析;搜索相应的实时或者是历史的(替代的查询计划)性能数据;当存在时候,提示可以使用备选的查询计划;(需要相应的cache来保存该备选的查询计划)(6)SQL Tuning Advisor,其已sql语句作为输入,然后使用自动调优模块对该sql语句进行自动调优; (7)自动负载库(automatic workload repository, awr, 对应mysql来说我们可以由performance_schema中的Top sql来代替),也被称为自动sql调优基础数据;
工作原理:一旦开启自动sql调优选项,则数据库按以下步骤进行工作;
1) 标识出awr中的所有sql候选项; 数据库分析awr中的统计信息,并以此计算出相应的潜在的候选sql列表;并选择出性能改进最多的进行推荐; 并行查询 dml, ddl,以及有并发问题的sql。
2)调用sql adivsor进行调优操作;
3)可以用报告来查询调优的结果;
报告内容:
1)通用信息;一般性的描述,例如:sql的数量等等;
2)综述:进行调优的sql数量;以及每个sql所能带来的性能提升;以及实际的执行后所带来的性能提升;
3)调优时候发现;
4)查询计划的解释;explain sql语句的执行结果;
5)错误信息;
在优化的过程中所需要考虑的问题:
(1)涉及到的问题CPU的瓶颈;是否是数据库与CPU进行绑定;
(2)内存结构;需要理解内存结构; SGA,PGA,buffer cached等是否是合适的大小;
(3)IO大小问题;IO子系统的性能是否如期望;
(4)配置问题,是否是数据库参数配置合理;
(5)并发问题;Buffer的使用情况是否合理;
统计信息包括: 应用层面的统计(事务的数量,相应时间等);数据库的统计信息;操作系统的统计信息;磁盘io的统计信息;网络的统计信息; latch contention;
统计信息的收集工作:
1)等待事件的数量;其会影响到系统的性能,等待事件相关的包括:latch contention,buffer contention,io contention等;
2)操作系统的统计信息:cup的统计信息;虚拟内存的统计信息;磁盘io的统计信息;网络的统计信息;
操作系统数据收集工具:cpu 使用:sar vmstat, mpstat, iostat; 内存使用: sar, vmstat; 磁盘使用:sar, iostat; 网络使用:netstat;buffer cache hit ratio: buffer cache的命中率;

Automatic SQL Tuning
从上述的讨论可以看出,CloudDBA和Oracle的所提供的服务完整,涵盖了静态和动态两个方面。其中静态更多的采样是基于规则的方式;而动态的优化策略又是基于统计信息来完成;而动态方式除了inception外,clouddba,oracle采用的是基于统计信息;
-
xxx的相关做法
当前xxx整体数据库集群对应集群的整体数据的描述缺乏统一描述;相对于其他的厂商所以提供的SQL Advisor,xxx所在集群的管理中所积累的大量的关于数据库集群的优化策略和方法均无法更加有效的发挥更大的效能;
现有我们所能够获取的到的信息包括:数据库实例各种信息,我们可以通过information_schema和performance_schema获得并通过各种类型的log来获取;通过information_schema和performance_schema我们可以获得该数据库实例所运行过程中的相关参数;同过各种log数据,我们可以描绘出整个数据库实例的访问模式;通过这两类信息我们便可以获得关于数据库的绝大部分的运行参数和数据;例如:我们可以通过information_schema.tables来获得各个所使用的storage engine类型;每张表中的记录数量等等;通过,log数据我们可以知道集群中的哪些实例是被频繁访问;哪些表访问量少等等;
可以通过xxx所提供的mysqlproxy,mysql-sharding,mysql audit以及相应的SDK所提供的数据库访问log来描绘出在某个特定的时间内整个集群内的访问情况;有了这些数据后,我们可以完成更多的工作提供了可能;
对于SQL advisor,我们可以分为两个阶段来完成:(1)静态分析阶段;(2)动态分析阶段; 在静态分析阶段,我们更多的是采用基于规则的方式来进行。该中模式下,我们对于动态数据的依赖较少可以较为快速的完成对应sql语句的分析并给出分析和优化报告; 但该种方式存在着一定的局限性:首先,过度的依赖于规则系统,一个完备和有效的规则会极大的提供所有给出的优化建议的合理和高效性;同时,该系统只是局限于当前的规则内,当一个新的模式的语句出现,如果未有相应的规则与之对应,则可能出现,系统对应该语句无法处理(未产生任何结果);再者,由于该种方式下,并未合理的利用集群中的关于数据的统计信息,因此并不一定能够给出该语句最优建议;例如:索引创建的是否合理;索引方式和全表扫描的方式哪个效率更高等等;
在基于规则的系统下,首先需要完成对应规则的标准化,将规则解释成sql advisor所能理解的模式。这里我们考虑采用关系数据库中相似的处理方法-基于规则查询优化策略;将规则系统转为ast树的方式;然后在sql语句执行优化的时候应该该规则系统;例如: utilityStmt <> :resultRelation 0 :hasAggs false :hasWindowFuncs false :hasTargetSRFs false :hasSubLinks false :hasDistinctOn false :hasRecursive false :hasModifyingCTE false :hasForUpdate false :hasRowSecurity false :cteList <> :rtable ({RTE :alias {ALIAS :aliasname old :colnames <>} :eref {ALIAS :aliasname old :colnames (“schemaname” “tablename” “indexname” “tablespace” “indexdef”) 。将相应的规则采用该种方式表示;该种方式表示可方便转为string或者已string的方式转为ast类型; 同时,为了能够保持相应的规则我们可以维护一个元数据表或者配置文件的方式;(然也可以有更好的方式来)。
对应静态的规则系统我们可以先已inception为基础框架并在该基础框架之上进行,规则引擎的构建; 在此基础上,我们需要完成的功能主要包括:(1)规则系统的描述定义;(2)规则系统的转换规则及应用;(3)规则系统的维护;
其中的重点和难点是:规则系统的定义化,给出规则形式化的描述;同时,将形式化后的规则系统转为ast的方式进行描述; ast化后的规则系统的应用;
为了方便维护规则系统,系统将提供相关的配置命令来该规则系统;
在创建完相应的规则系统后,当输入一个SQL语句后,首先完成对应该SQL语句的基本语法检查,语义检查后(这里需要系统的元数据支持,例如该表是否存在,所查询的列是否存在等等,类型类型是否匹配等等),SQL语句会应该规则系统进行检查;已经事先创建的规则系统对该查询语句进行改写操作;并将改写后的结果作为后续的输入,同时将相应的改写操作中间步骤作为输出报告的形式告知用户;
对动态的方式,我们需要更为全面的数据支持。例如每个集群实例中的数据分布情况;与clouddba和oracle一样我们需要完成对应集群中实例的统计信息的收集; (该部分涉及的较多这里先不展开叙述)
VS 2008不能运行debug
安装完vs2008 (x64)后,运行时报如下错误:
”The Visual Studio Debugger did not load because of previous errors. For assistance, contact the package vendor. To attempt to load this package again, type ‘devenv /resetskippkgs’ at the command prompt.“
导致程序不能进行debug操作,解决方案如下(from stackoverflow)
After looking back and forth over the internet, coming across a lot of different answers, i finally managed to get this working. This was my solution:
- Close all open instances of Visual Studio.
- Open the Command Prompt in an Administrator context by navigating to Start\All Programs\Accessories, right-clicking Command Prompt and choosing Run as Administrator.
- Navigate to the install path of VS2008 – in my case (default on Vista x64) it was **C:\Program Files (x86)\Microsoft Visual Studio 2008 9.0\Common7\IDE**
- Run the command devenv /setup. It takes a little while, but be patient.
- Start Visual Studio.
After following these steps, the setup is reset to default, so you’ll have to reconfigure all startup options, fonts for the text editors etc. This could possibly be helped by running devenv /resetskippkgs instead, however it did not on my machine.
经过上述操作,测试可以有效解决该问题。