[图来自互联网,侵删]
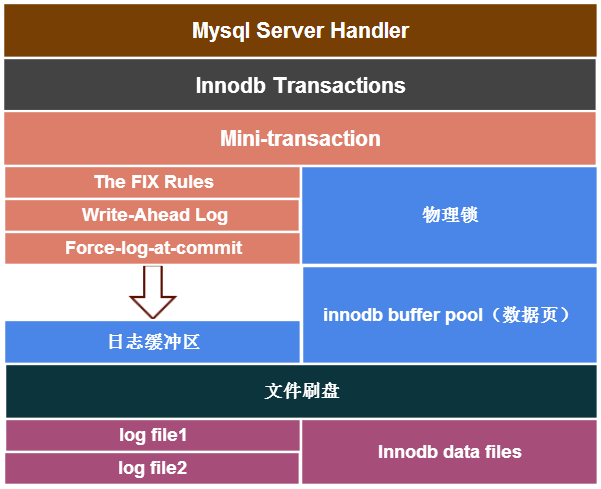

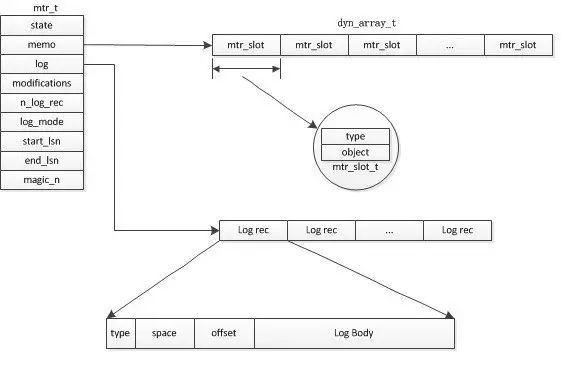


[图来自互联网,侵删]
The list referenced papers are listed from. 《Hybrid Transactional/Analytical Processing: A Survey.》, from IBM Research.
[1] Apache Parquet. https://parquet.apache.org/.
[2] R. Appuswarmy, M. Karpathiotakis, D. Porobic, and A. Ailamaki. The Case For Heterogeneous HTAP. In
CIDR, 2017.
[3] M. Armbrust, R. S. Xin, C. Lian, Y. Huai, D. Liu,J. K. Bradley, X. Meng, T. Kaftan, M. J. Franklin,
A. Ghodsi, and M. Zaharia. Spark SQL: Relational Data Processing in Spark. In SIGMOD, pages 1383–1394, 2015.
[4] J. Arulraj, A. Pavlo, and P. Menon. Bridging the Archipelago Between Row-Stores and Column-Stores for Hybrid Workloads. In SIGMOD, pages 583–598, 2016.
[5] R. Barber, C. Garcia-Arellano, R. Grosman, R. Mueller, V. Raman, R. Sidle, M. Spilchen, A. Storm, Y. Tian, P. T¨ozun, D. Zilio, M. Huras, ¨
G. Lohman, C. Mohan, F. Ozcan, and H. Pirahesh. ¨Evolving Databases for New-Gen Big Data Applications. In CIDR, 2017.
[6] A. Boehm, J. Dittrich, N. Mukherjee, I. Pandis, and R. Sen. Operational analytics data management systems. PVLDB, 9:1601–1604, 2016.
[7] P. Boncz, M. Zukowski, and N. Nes. MonetDB/X100: Hyper-Pipelining Query Execution. In CIDR, 2005.
[8] Apache Cassandra. http://cassandra.apache.org.
[9] A. Costea, A. Ionescu, B. R˘aducanu, M. Switakowski, C. Bˆarca, J. Sompolski, A. Luszczak, M. Szafra´nski, G. de Nijs, and P. Boncz. Vectorh: Taking
sql-on-hadoop to the next level. In SIGMOD ’16, pages 1105–1117, 2016.
[10] Danial Abadi and Shivnath Babu and Fatma Ozcan ¨ and Ippokratis Pandis. Tutorial: SQL-on-Hadoop Systems. PVLDB, 8, 2015.
[11] IBM dashDB. http://www.ibm.com/analytics/us/en/technology/cloud-data-services/dashdb.
[12] DataStax Spark Cassandra Connector. https://github.com/datastax/spark-cassandra-connector.
[13] C. Diaconu, C. Freedman, E. Ismert, P.-˚A. Larson, P. Mittal, R. Stonecipher, N. Verma, and M. Zwilling. Hekaton: SQL Server’s memory-optimized OLTP
engine. In SIGMOD, pages 1243–1254, 2013.
[14] F. F¨arber, N. May, W. Lehner, P. Große, I. Muller, ¨ H. Rauhe, and J. Dees. The SAP HANA Database –An Architecture Overview. IEEE DEBull,35(1):28–33, 2012.
[15] S. Gray, F. Ozcan, H. Pereyra, B. van der Linden, and ¨A. Zubiri. IBM Big SQL 3.0: SQL-on-Hadoop without compromise. http://public.dhe.ibm.com/common/ssi/
ecm/en/sww14019usen/SWW14019USEN.PDF, 2014.
[16] SAP HANA Vora. http://go.sap.com/product/data-mgmt/hana-vora-hadoop.html.
[17] Apache HBase. https://hbase.apache.org/.
[18] Hive Transactions. http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.3.0/bk dataintegration/content/hive-013-feature-transactions.html.[19] A. Kemper and T. Neumann. HyPer – A Hybrid OLTP&OLAP Main Memory Database System Based on Virtual Memory Snapshots. In ICDE, pages 195–206, 2011.
[20] M. Kornacker, A. Behm, V. Bittorf, T. Bobrovytsky,C. Ching, A. Choi, J. Erickson, M. Grund, D. Hecht, M. Jacobs, I. Joshi, L. Kuff, D. Kumar, A. Leblang,
N. Li, I. Pandis, H. Robinson, D. Rorke, S. Rus, J. Russell, D. Tsirogiannis, S. Wanderman-Milne, and M. Yoder. Impala: A modern, open-source SQL engine for Hadoop. In CIDR, 2015.
[21] Apache Kudu. https://kudu.apache.org/.
[22] T. Lahiri, M.-A. Neimat, and S. Folkman. Oracle TimesTen: An In-Memory Database for Enterprise Applications. IEEE DEBull, 36(3):6{13, 2013.
[23] A. Lamb, M. Fuller, R. Varadarajan, N. Tran, B. Vandiver, L. Doshi, and C. Bear. The Vertica Analytic Database: C-store 7 Years Later. PVLDB, 5(12):1790{1801, 2012.
[24] MemSQL. http://www.memsql.com/.
[25] C. Mohan. History Repeats Itself: Sensible and NonsenSQL Aspects of the NoSQL Hoopla. In EDBT, 2013.
[26] B. Mozafari, J. Ramnarayan, S. Menon, Y. Mahajan, S. Chakraborty, H. Bhanawat, and K. Bachhav.SnappyData: A Unified Cluster for Streaming, Transactions and Interactice Analytics. In CIDR, 2017.
[27] Apache ORC. https://orc.apache.org/.
[28] A. Pavlo, J. Arulraj, L. Ma, P. Menon, T. C. Mowry, M. Perron, A. Tomasic, D. V. Aken, Z. Wang, and T. Zhang. Self-Driving Database Management
Systems. In CIDR, 2017.
[29] Apache Phoenix. http://phoenix.apache.org.
[30] V. Raman, G. Attaluri, R. Barber, N. Chainani, D. Kalmuk, V. KulandaiSamy, J. Leenstra, S. Lightstone, S. Liu, G. M. Lohman, T. Malkemus,
R. Mueller, I. Pandis, B. Schiefer, D. Sharpe, R. Sidle, A. Storm, and L. Zhang. DB2 with BLU Acceleration: So Much More than Just a Column Store. PVLDB, 6:1080{1091, 2013.
[31] RocksDB. http://rocksdb.org/.
[32] Roshan Sumbaly and others. Serving large-scale batch computed data with project Voldemort. In Proc. of the 10th USENIX conference on File and Storage Technologies, 2012.
[33] Splice Machine. http://www.splicemachine.com/.
[34] M. Stonebraker and U. Cetintemel. “One Size Fits All”: An Idea Whose Time Has Come and Gone. In ICDE, pages 2{11, 2005.
[35] M. Stonebraker and A. Weisberg. The VoltDB Main
Memory DBMS. IEEE Data Eng. Bull., 36(2):21{27, 2013.
[36] A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, N. Zhang, S. Anthony, H. Liu, and R. Murthy. Hive –
A Petabyte Scale Data Warehouse Using Hadoop. In ICDE, 2010.
[37] S. Tu, W. Zheng, E. Kohler, B. Liskov, and S. Madden. Speedy Transactions in Multicore In-memory Databases. In SOSP, pages 18{32, 2013.
[38] Z. Zhang. Spark-on-HBase: Dataframe Based HBase Connector. http://hortonworks.com/blog/spark-hbase-dataframe-based-hbase-connector.
在Optimize_table_order::Optimize_table_order函数中,完成对于表的join顺序的优化。 首先,要设置相应的我们优化的搜索空间表的深度问题; 然后由choose_table_order来
获取相应的表之间的顺序关系;
recalculate_lateral_deps 重新计算相关依赖的关系;
在choose_table_order的过程中,我们会选择greedy_search进行搜索空间的处理,
#0 Optimize_table_order::best_extension_by_limited_search (this=0x7f0744577c60, remaining_tables=31, idx=0, current_search_depth=62)
at /home/leehao/mysql-server/sql/sql_planner.cc:2701
#1 0x00000000038603c7 in Optimize_table_order::greedy_search (this=0x7f0744577c60, remaining_tables=31)
at /home/leehao/mysql-server/sql/sql_planner.cc:2323
#2 0x000000000385fb6f in Optimize_table_order::choose_table_order (this=0x7f0744577c60) at /home/leehao/mysql-server/sql/sql_planner.cc:1999
#3 0x000000000381df54 in JOIN::make_join_plan (this=0x7f068cad91d8) at /home/leehao/mysql-server/sql/sql_optimizer.cc:5159
#4 0x000000000381154f in JOIN::optimize (this=0x7f068cad91d8) at /home/leehao/mysql-server/sql/sql_optimizer.cc:591
#5 0x00000000038c05c3 in Query_block::optimize (this=0x7f068c15f938, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:1805
#6 0x00000000039647af in Query_expression::optimize (this=0x7f068c15f1d8, thd=0x7f068c001040, materialize_destination=0x0,
create_iterators=true) at /home/leehao/mysql-server/sql/sql_union.cc:678
#7 0x00000000038be156 in Sql_cmd_dml::execute_inner (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:759
#8 0x00000000038bd766 in Sql_cmd_dml::execute (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:574
#9 0x00000000038433ee in mysql_execute_command (thd=0x7f068c001040, first_level=true) at /home/leehao/mysql-server/sql/sql_parse.cc:4436
#10 0x0000000003845396 in dispatch_sql_command (thd=0x7f068c001040, parser_state=0x7f0744579b60)
at /home/leehao/mysql-server/sql/sql_parse.cc:5033
#11 0x000000000383b915 in dispatch_command (thd=0x7f068c001040, com_data=0x7f074457ac20, command=COM_QUERY)
at /home/leehao/mysql-server/sql/sql_parse.cc:1863
#12 0x0000000003839d51 in do_command (thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_parse.cc:1342
在Optimize_table_order::advance_sj_state函数中,我们处理了semi-join optimization,当我们把新的表添加到相应的join prefix中的时候;
get_best_combination 完成依据之前的best_position中的内容来设置相应的join order内容;
在JOIN::create_root_access_path_for_join 函数中,我们依据qep来创建相应的访问路径; 例如: filesort来创建 FileSort; windows类型
则创建 NewWindowingAccessPath这样的类型;以此类推; SingleMaterializeQueryBlock。
如果需要创建相应的parallel访问的时候也需要在这里进行添加相应的access path。
Query_expression::optimize函数中,由CreateIteratorFromAccessPath函数依据我们的access path来创解相应的(access的path->type)iterator。
接下来就是执行阶段: 经过重构后的mysql 查询引擎,越来越像PG查询引擎的架构,代码比较清晰了。
#0 Query_expression::execute (this=0x7f068c15f1d8, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_union.cc:1270
#1 0x00000000038be1e4 in Sql_cmd_dml::execute_inner (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:774
#2 0x00000000038bd766 in Sql_cmd_dml::execute (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:574
#3 0x00000000038433ee in mysql_execute_command (thd=0x7f068c001040, first_level=true) at /home/leehao/mysql-server/sql/sql_parse.cc:4436
#4 0x0000000003845396 in dispatch_sql_command (thd=0x7f068c001040, parser_state=0x7f0744579b60)
at /home/leehao/mysql-server/sql/sql_parse.cc:5033
#5 0x000000000383b915 in dispatch_command (thd=0x7f068c001040, com_data=0x7f074457ac20, command=COM_QUERY)
at /home/leehao/mysql-server/sql/sql_parse.cc:1863
由Query_expression中的execute函数来完成相应的对于执行计划的执行操作; 由具体的函数 Query_expression::ExecuteIteratorQuery来进行执行;
首先,会使用query_result->send_result_set_metadata 来发送结果集的元数据信息,即:都有哪些列,列的类型,大小等等信息;
具体执行有Query_result_send::send_result_set_metadata来完成。 会调用thd的 THD::send_result_metadata 函数来完成对于结果集的元数据信息
的发送;
#0 SortingIterator::Init (this=0x7f068cceb4a0) at /home/leehao/mysql-server/sql/sorting_iterator.cc:439
#1 0x000000000396653d in Query_expression::ExecuteIteratorQuery (this=0x7f068c15f1d8, thd=0x7f068c001040)
at /home/leehao/mysql-server/sql/sql_union.cc:1224
#2 0x00000000039668cb in Query_expression::execute (this=0x7f068c15f1d8, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_union.cc:1284
#3 0x00000000038be1e4 in Sql_cmd_dml::execute_inner (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:774
#4 0x00000000038bd766 in Sql_cmd_dml::execute (this=0x7f068cad2b48, thd=0x7f068c001040) at /home/leehao/mysql-server/sql/sql_select.cc:574
#5 0x00000000038433ee in mysql_execute_command (thd=0x7f068c001040, first_level=true) at /home/leehao/mysql-server/sql/sql_parse.cc:4436
#6 0x0000000003845396 in dispatch_sql_command (thd=0x7f068c001040, parser_state=0x7f0744579b60)
at /home/leehao/mysql-server/sql/sql_parse.cc:5033
从下面的调用栈,我们可以看到,首先执行的是一个sortIterator, 因为我们语句最外使用的是order by语句。
set debug=”+d,info,error,query,enter,general,where:O,/tmp/mysqld.trace”